Data Stories now learns user preferences in a fully transparent way. Read more about how it works and why its exciting
In product development, effort rarely correlates with visbile progress. It takes countless sleepless nights to get the nuances of agent orchestration work hy- mostly invisible to the users. (There is a reason, so many conversational agent projects never get into production or are rolled back when their quality disappoints. It’s hard.)
This time was different: With strong foundations in place, it didn’t take much to unlock a new Data Story capability that earned great reviews from users.
For context, Data Stories very early kept track of the user’s intent within a session. This goes beyond keeping track of conversation history, because most Data Story answers are not simply text but interactive applications in their own right. Consider this example, where the user asks for a map and then refines:
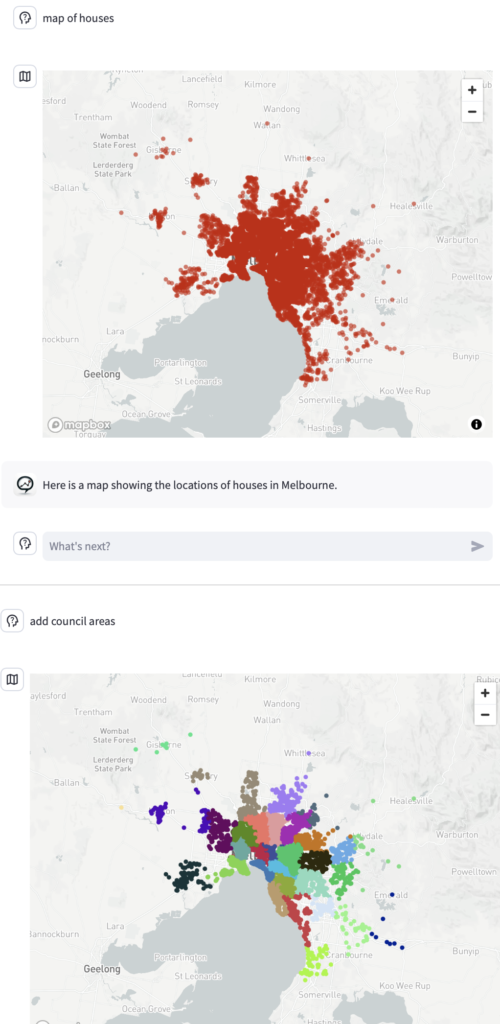
The ability to ask “Hey, analyst, this graph we looked at earlier needs some tweaking” or “can we revisit that earlier hypothesis and look at it with X in mind” glues together the different threads just as we do it in productive conversations as humans.
Our new “preference learning” takes this idea to a higher conceptional level. As an analyst, Dirk would carry a Moleskine notebook to make sure he remembers his stakeholders expectations, needs and interests. Data Stories now has such a notebook in its digital toolbox and it’s amazing, how well it makes use of it. Here is a simple example how the thread above can be extended in the latest app version:
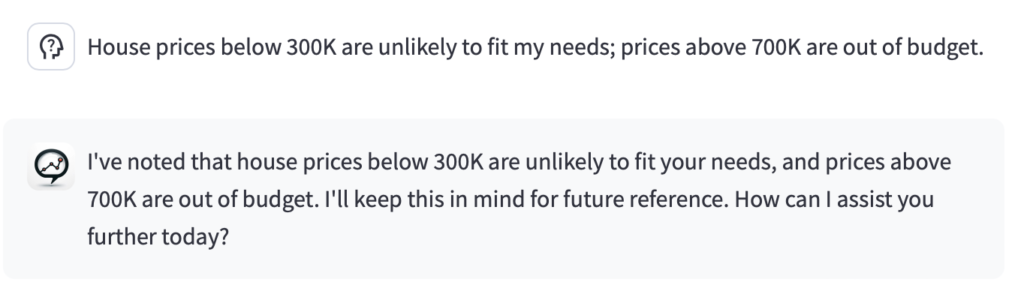
When you see such a response, Data Stories has identified a user insight and added it to the user’s local database.
In future, when answering to this user all past insights are scanned and the most relevant are attched the user question in the background. This additional intelligence comes without extra delay as it runs in parallel to the already existing scan of what database tables are relevant.
As a result many answers are personalized — just as the time range in the following graph once we stated the preference above:
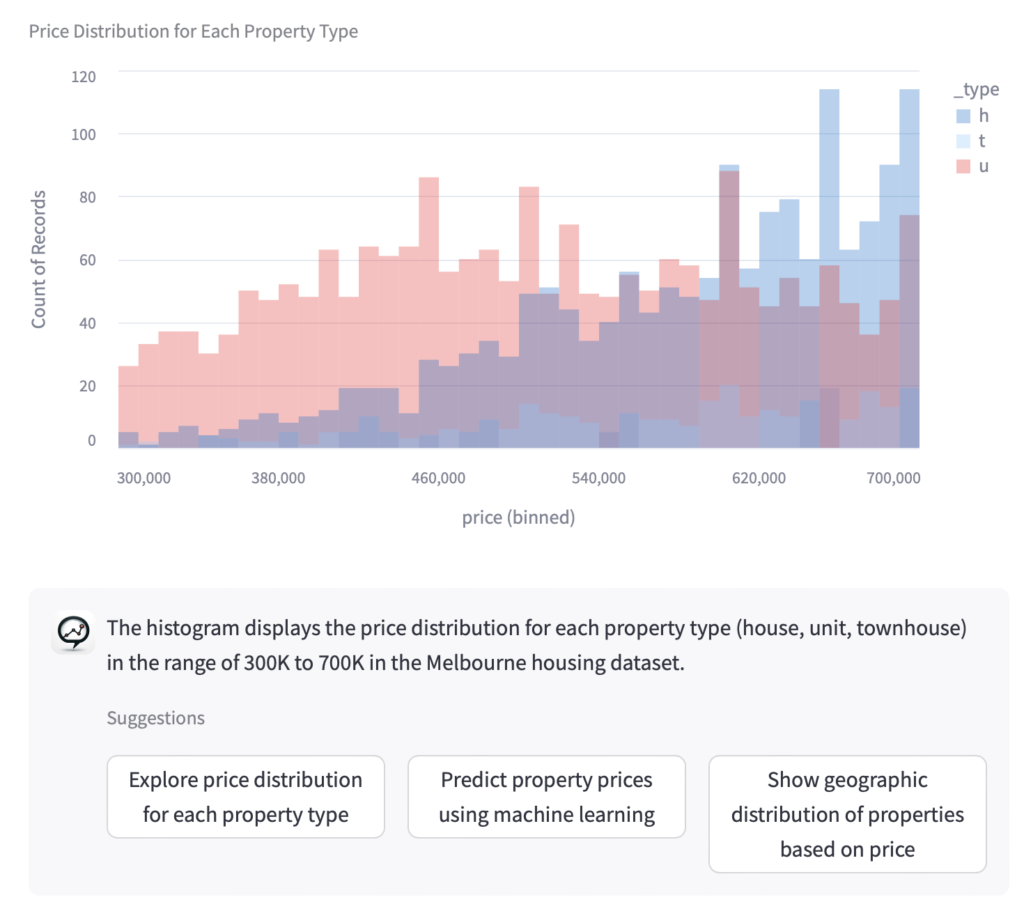
Note that applying the learned preferences happens implicitly (though the agent would tell you why it chose that range if you asked). This is desired because the number of insights will proliferate.
Transparency is one of Data Stories’ key principles, so the user can review (and even edit) all knowledge the app has ever collected about her:
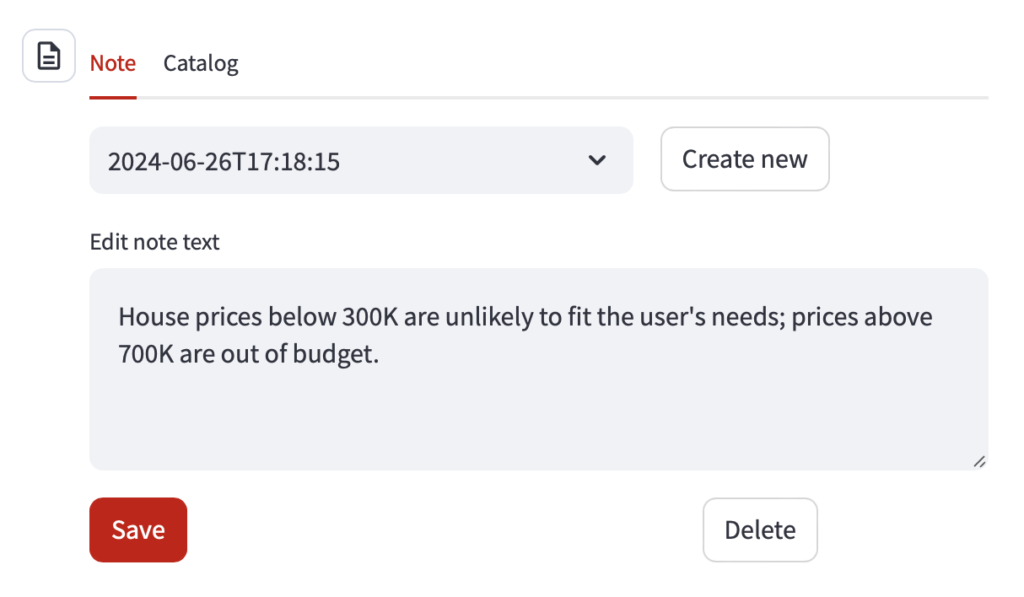
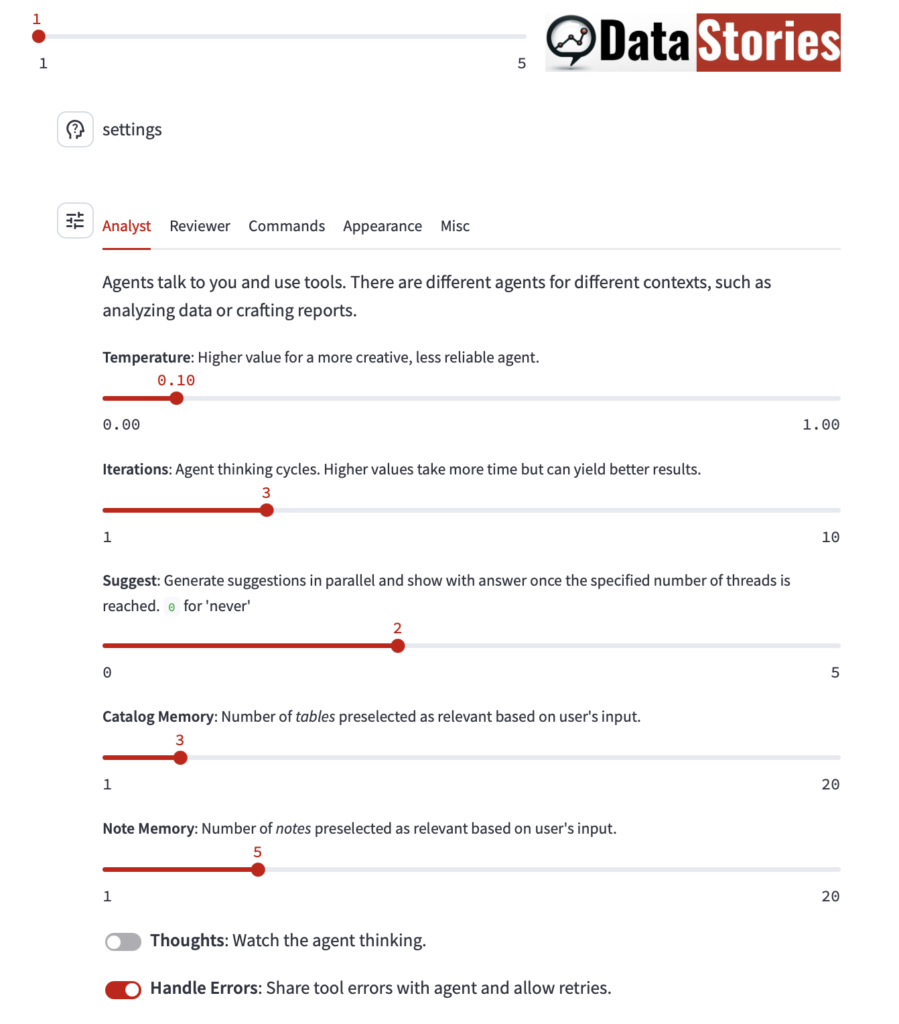
There is also a new parameter in the application setting, Note Memory, controlling the number of semantically relevant memories Data Stories considers for a given user question:
Consider how different this approach is from the silent profiling being done by most cloud services, eg. in social media. In contrast, Data Stories stores everything locally and is easy to inspect.
We now have many different retrieval augmentations happening in parallel (schema discovery, imported documents, web search, connected documents, user preferences) and we can’t wait to see what compositions will emerge as each of these is accessed with several agent tools sequenced in very diverse reasoning chains.